I recently finished a paper that presents a novel social computing system called the Wikipedia Adventure. The system was a gamified tutorial for new Wikipedia editors. Working with the tutorial creators, we conducted both a survey of its users and a randomized field experiment testing its effectiveness in encouraging subsequent contributions. We found that although users loved it, it did not affect subsequent participation rates.
Start screen for the Wikipedia Adventure.
A major concern that many online communities face is how to attract and retain new contributors. Despite it s success, Wikipedia is no different. In fact, researchers have shown that after experiencing a massive initial surge in activity, the number of active editors on Wikipedia has been in slow decline since 2007.
The number of active, registered editors ( 5 edits per month) to Wikipedia over time. From Halfaker, Geiger, and Morgan 2012.
Research has attributed a large part of this decline to the hostile environment that newcomers experience when begin contributing. New editors often attempt to make contributions which are subsequently reverted by more experienced editors for not following Wikipedia s increasingly long list of rules and guidelines for effective participation.
This problem has led many researchers and Wikipedians to wonder how to more effectively onboard newcomers to the community. How do you ensure that new editors Wikipedia quickly gain the knowledge they need in order to make contributions that are in line with community norms?
To this end, Jake Orlowitz and Jonathan Morgan from the Wikimedia Foundation worked with a team of Wikipedians to create a structured, interactive tutorial called The Wikipedia Adventure. The idea behind this system was that new editors would be invited to use it shortly after creating a new account on Wikipedia, and it would provide a step-by-step overview of the basics of editing.
The Wikipedia Adventure was designed to address issues that new editors frequently encountered while learning how to contribute to Wikipedia. It is structured into different missions that guide users through various aspects of participation on Wikipedia, including how to communicate with other editors, how to cite sources, and how to ensure that edits present a neutral point of view. The sequence of the missions gives newbies an overview of what they need to know instead of having to figure everything out themselves. Additionally, the theme and tone of the tutorial sought to engage new users, rather than just redirecting them to the troves of policy pages.
Those who play the tutorial receive automated badges on their user page for every mission they complete. This signals to veteran editors that the user is acting in good-faith by attempting to learn the norms of Wikipedia.
An example of a badge that a user receives after demonstrating the skills to communicate with other users on Wikipedia.
Once the system was built, we were interested in knowing whether people enjoyed using it and found it helpful. So we conducted a survey asking editors who played the Wikipedia Adventure a number of questions about its design and educational effectiveness. Overall, we found that users had a very favorable opinion of the system and found it useful.
Survey responses about how users felt about TWA.Survey responses about what users learned through TWA.
We were heartened by these results. We d sought to build an orientation system that was engaging and educational, and our survey responses suggested that we succeeded on that front. This led us to ask the question could an intervention like the Wikipedia Adventure help reverse the trend of a declining editor base on Wikipedia? In particular, would exposing new editors to the Wikipedia Adventure lead them to make more contributions to the community?
To find out, we conducted a field experiment on a population of new editors on Wikipedia. We identified 1,967 newly created accounts that passed a basic test of making good-faith edits. We then randomly invited 1,751 of these users via their talk page to play the Wikipedia Adventure. The rest were sent no invitation. Out of those who were invited, 386 completed at least some portion of the tutorial.
We were interested in knowing whether those we invited to play the tutorial (our treatment group) and those we didn t (our control group) contributed differently in the first six months after they created accounts on Wikipedia. Specifically, we wanted to know whether there was a difference in the total number of edits they made to Wikipedia, the number of edits they made to talk pages, and the average quality of their edits as measured by content persistence.
We conducted two kinds of analyses on our dataset. First, we estimated the effect of inviting users to play the Wikipedia Adventure on our three outcomes of interest. Second, we estimated the effect of playing the Wikipedia Adventure, conditional on having been invited to do so, on those same outcomes.
To our surprise, we found that in both cases there were no significant effects on any of the outcomes of interest. Being invited to play the Wikipedia Adventure therefore had no effect on new users volume of participation either on Wikipedia in general, or on talk pages specifically, nor did it have any effect on the average quality of edits made by the users in our study. Despite the very positive feedback that the system received in the survey evaluation stage, it did not produce a significant change in newcomer contribution behavior. We concluded that the system by itself could not reverse the trend of newcomer attrition on Wikipedia.
Why would a system that was received so positively ultimately produce no aggregate effect on newcomer participation? We ve identified a few possible reasons. One is that perhaps a tutorial by itself would not be sufficient to counter hostile behavior that newcomers might experience from experienced editors. Indeed, the friendly, welcoming tone of the Wikipedia Adventure might contrast with strongly worded messages that new editors receive from veteran editors or bots. Another explanation might be that users enjoyed playing the Wikipedia Adventure, but did not enjoy editing Wikipedia. After all, the two activities draw on different kinds of motivations. Finally, the system required new users to choose to play the tutorial. Maybe people who chose to play would have gone on to edit in similar ways without the tutorial.
Ultimately, this work shows us the importance of testing systems outside of lab studies. The Wikipedia Adventure was built by community members to address known gaps in the onboarding process, and our survey showed that users responded well to its design.
While it would have been easy to declare victory at that stage, the field deployment study painted a different picture. Systems like the Wikipedia Adventure may inform the design of future orientation systems. That said, more profound changes to the interface or modes of interaction between editors might also be needed to increase contributions from newcomers.
Last week, we presented a new paper that describes how children are thinking through some of the implications of new forms of data collection and analysis. The presentation was given at the ACM CHI conference in Denver last week and the paper is open access and online.
Over the last couple years, we ve worked on a large project to support children in doing and not just learning about data science. We built a system, Scratch Community Blocks, that allows the 18 million users of the Scratch online community to write their own computer programs in Scratch of course to analyze data about their own learning and social interactions. An example of one of those programs to find how many of one s follower in Scratch are not from the United States is shown below.
Last year, we deployed Scratch Community Blocks to 2,500 active Scratch users who, over a period of several months, used the system to create more than 1,600 projects.
As children used the system, Samantha Hautea, a student in UW s Communication Leadership program, led a group of us in an online ethnography. We visited the projects children were creating and sharing. We followed the forums where users discussed the blocks. We read comment threads left on projects. We combined Samantha s detailed field notes with the text of comments and forum posts, with ethnographic interviews of several users, and with notes from two in-person workshops. We used a technique called grounded theory to analyze these data.
What we found surprised us. We expected children to reflect on being challenged by and hopefully overcoming the technical parts of doing data science. Although we certainly saw this happen, what emerged much more strongly from our analysis was detailed discussion among children about the social implications of data collection and analysis.
In our analysis, we grouped children s comments into five major themes that represented what we called critical data literacies. These literacies reflect things that children felt were important implications of social media data collection and analysis.
First, children reflected on the way that programmatic access to data even data that was technically public introduced privacy concerns. One user described the ability to analyze data as, creepy , but at the same time, very cool. Children expressed concern that programmatic access to data could lead to stalking and suggested that the system should ask for permission.
Second, children recognized that data analysis requires skepticism and interpretation. For example, Scratch Community Blocks introduced a bug where the block that returned data about followers included users with disabled accounts. One user, in an interview described to us how he managed to figure out the inconsistency:
At one point the follower blocks, it said I have slightly more followers than I do. And, that was kind of confusing when I was trying to make the project. [ ] I pulled up a second [browser] tab and compared the [data from Scratch Community Blocks and the data in my profile].
Third, children discussed the hidden assumptions and decisions that drive the construction of metrics. For example, the number of views received for each project in Scratch is counted using an algorithm that tries to minimize the impact of gaming the system (similar to, for example, Youtube). As children started to build programs with data, they started to uncover and speculate about the decisions behind metrics. For example, they guessed that the view count might only include unique views and that view counts may include users who do not have accounts on the website.
Fourth, children building projects with Scratch Community Blocks realized that an algorithm driven by social data may cause certain users to be excluded. For example, a 13-year-old expressed concern that the system could be used to exclude users with few social connections saying:
I love these new Scratch Blocks! However I did notice that they could be used to exclude new Scratchers or Scratchers with not a lot of followers by using a code: like this:
when flag clicked
if then user s followers < 300
stop all.
I do not think this a big problem as it would be easy to remove this code but I did just want to bring this to your attention in case this not what you would want the blocks to be used for.
Fifth, children were concerned about the possibility that measurement might distort the Scratch community s values. While giving feedback on the new system, a user expressed concern that by making it easier to measure and compare followers, the system could elevate popularity over creativity, collaboration, and respect as a marker of success in Scratch.
I think this was a great idea! I am just a bit worried that people will make these projects and take it the wrong way, saying that followers are the most important thing in on Scratch.
Kids conversations around Scratch Community Blocks are good news for educators who are starting to think about how to engage young learners in thinking critically about the implications of data. Although no kid using Scratch Community Blocks discussed each of the five literacies described above, the themes reflect starting points for educators designing ways to engage kids in thinking critically about data.
Our work shows that if children are given opportunities to actively engage and build with social and behavioral data, they might not only learn how to do data analysis, but also reflect on its implications.
This blog-post and the work that it describes is a collaborative project by Samantha Hautea, Sayamindu Dasgupta, and Benjamin Mako Hill. We have also received support and feedback from members of the Scratch team at MIT (especially Mitch Resnick and Natalie Rusk), as well as from Hal Abelson from MIT CSAIL. Financial support came from the US National Science Foundation.
Attracting newcomers is among the most widely studied problems in online community research. However, with all the attention paid to challenge of getting new users, much less research has studied the flip side of that coin: large influxes of newcomers can pose major problems as well!
The most widely known example of problems caused by an influx of newcomers into an online community occurred in Usenet. Every September, new university students connecting to the Internet for the first time would wreak havoc in the Usenet discussion forums. When AOL connected its users to the Usenet in 1994, it disrupted the community for so long that it became widely known as The September that never ended .
Our study considered a similar influx in NoSleep an online community within Reddit where writers share original horror stories and readers comment and vote on them. With strict rules requiring that all members of the community suspend disbelief, NoSleep thrives off the fact that readers experience an immersive storytelling environment. Breaking the rules is as easy as questioning the truth of someone s story. Socializing newcomers represents a major challenge for NoSleep.
Number of subscribers and moderators on /r/NoSleep over time.
On May 7th, 2014, NoSleep became a default subreddit i.e., every new user to Reddit automatically joined NoSleep. After gradually accumulating roughly 240,000 members from 2010 to 2014, the NoSleep community grew to over 2 million subscribers in a year. That said, NoSleep appeared to largely hold things together. This reflects the major question that motivated our study: How did NoSleep withstand such a massive influx of newcomers without enduring their own Eternal September?
To answer this question, we interviewed a number of NoSleep participants, writers, moderators, and admins. After transcribing, coding, and analyzing the results, we proposed that NoSleep survived because of three inter-connected systems that helped protect the community s norms and overall immersive environment.
First, there was a strong and organized team of moderators who enforced the rules no matter what. They recruited new moderators knowing the community s population was going to surge. They utilized a private subreddit for NoSleep s staff. They were able to socialize and educate new moderators effectively. Although issuing sanctions against community members was often difficult, our interviewees explained that NoSleep s moderators were deeply committed and largely uncompromising.
That commitment resonates within the second system that protected NoSleep: regulation by normal community members. From our interviews, we found that the participants felt a shared sense of community that motivated them both to socialize newcomers themselves as well as to report inappropriate comments and downvote people who violate the community s norms.
Finally, we found that the technological systems protected the community as well. For instance, post-throttling was instituted to limit the frequency at which a writer could post their stories. Additionally, Reddit s Automoderator , a programmable AI bot, was used to issue sanctions against obvious norm violators while running in the background. Participants also pointed to the tools available to them the report feature and voting system in particular to explain how easy it was for them to report and regulate the community s disruptors.
This blog post was written with Charlie Kiene. The paper and work this post describes is collaborative work with Charlie Kiene and Andr s Monroy-Hern ndez. The paper was published in the Proceedings of CHI 2016 and is released as open access so anyone can read the entire paper here. A version of this post was published on the Community Data Science Collective blog.
Recently some of my coworkers and I experienced an issue with using the upper left touchpad
button on our Dell Latitude E7470 and similar laptops (E5xxx from the current generation).
Some time in January we could no longer hold down this button and select text with the
touchpad. Using the left button below the touchpad still worked.
This hit my coworker running Fedora and myself running Debian/stretch. So I first thought
that it's likely a libinput issue (same version in Debian/stretch and Fedora and I recently
pulled that in as an update), somehow blacklisting the upper left key because it's connected
to the trackpoint. So I filled
#99594 upstream. While this
was not very helpful at first, and according to Peter very unlikely to be related to libinput,
another coworker using Debian/jessie found this issue to hit him when he upgraded the backports
kernel in use from 4.8 to 4.9. That finally led to the conclusion that it's a bug in
the Linux alps driver, which is already fixed in 4.10 and probably 4.9.6.
Until the Debian kernel team pulls in a fresh 4.9 point release I'm using 4.10-rc6 from
experimental. For Debian/jessie + backports kernel user it might be more convenient
to just stay at 4.8 in case this issue annoys you.
Kudos to Peter, Benjamin, TW and WW for the help in locating the origin of this issue!
Lessons learned:
I should've started with the painful downgrade of xorg and libinput via snapshot.d.o before opening the bugreport.
A lot more of the touchpad related hardware support is nowadays in the kernel and not in the xorg layer. Either that was just my personal historic misunderstanding, or it was different 10 years ago.
There is an interesting set of slides from Benjamin related to debuging input device issues.
Scratch is a block-based programming language created by the Lifelong Kindergarten Group (LLK) at the MIT Media Lab. Scratch gives kids the power to use programming to create their own interactive animations and computer games. Since 2007, the online community that allows Scratch programmers to share, remix, and socialize around their projects has drawn more than 16 million users who have shared nearly 20 million projects and more than 100 million comments. It is one of the most popular ways for kids to learn programming and among the larger online communities for kids in general.
Front page of the Scratch online community (https://scratch.mit.edu) during the period covered by the dataset.
Since 2010, I havepublishedaseriesofpapers using quantitative data collected from the database behind the Scratch online community. As the source of data for many of my first quantitative and data scientific papers, it s not a major exaggeration to say that I have built my academic career on the dataset.
I was able to do this work because I happened to be doing my masters in a research group that shared a physical space ( The Cube ) with LLK and because I was friends with Andr s Monroy-Hern ndez, who started in my masters cohort at the Media Lab. A year or so after we met, Andr s conceived of the Scratch online community and created the first version for his masters thesis project. Because I was at MIT and because I knew the right people, I was able to get added to the IRB protocols and jump through the hoops necessary to get access to the database.
Over the years, Andr s and I have heard over and over, in conversation and in reviews of our papers, that we were privileged to have access to such a rich dataset. More than three years ago, Andr s and I began trying to figure out how we might broaden this access. Andr s had the idea of taking advantage of the launch of Scratch 2.0 in 2013 to focus on trying to release the first five years of Scratch 1.x online community data (March 2007 through March 2012) most of the period that the codebase he had written ran the site.
After more work than I have put into any single research paper or project, Andr s and I have published a data descriptor in Nature s new journal Scientific Data. This means that the data is now accessible to other researchers. The data includes five years of detailed longitudinal data organized in 32 tables with information drawn from more than 1 million Scratch users, nearly 2 million Scratch projects, more than 10 million comments, more than 30 million visits to Scratch projects, and much more. The dataset includes metadata on user behavior as well the full source code for every project. Alongside the data is the source code for all of the software that ran the website and that users used to create the projects as well as the code used to produce the dataset we ve released.
Releasing the dataset was a complicated process. First, we had navigate important ethical concerns about the the impact that a release of any data might have on Scratch s users. Toward that end, we worked closely with the Scratch team and the the ethics board at MIT to design a protocol for the release that balanced these risks with the benefit of a release. The most important features of our approach in this regard is that the dataset we re releasing is limited to only public data. Although the data is public, we understand that computational access to data is different in important ways to access via a browser or API. As a result, we re requiring anybody interested in the data to tell us who they are and agree to a detailed usage agreement. The Scratch team will vet these applicants. Although we re worried that this creates a barrier to access, we think this approach strikes a reasonable balance.
Beyond the the social and ethical issues, creating the dataset was an enormous task. Andr s and I spent Sunday afternoons over much of the last three years going column-by-column through the MySQL database that ran Scratch. We looked through the source code and the version control system to figure out how the data was created. We spent an enormous amount of time trying to figure out which columns and rows were public. Most of our work went into creating detailed codebooks and documentation that we hope makes the process of using this data much easier for others (the data descriptor is just a brief overview of what s available). Serializing some of the larger tables took days of computer time.
In this process, we had a huge amount of help from many others including an enormous amount of time and support from Mitch Resnick, Natalie Rusk, Sayamindu Dasgupta, and Benjamin Berg at MIT as well as from many other on the Scratch Team. We also had an enormous amount of feedback from a group of a couple dozen researchers who tested the release as well as others who helped us work through through the technical, social, and ethical challenges. The National Science Foundation funded both my work on the project and the creation of Scratch itself.
Because access to data has been limited, there has been less research on Scratch than the importance of the system warrants. We hope our work will change this. We can imagine studies using the dataset by scholars in communication, computer science, education, sociology, network science, and beyond. We re hoping that by opening up this dataset to others, scholars with different interests, different questions, and in different fields can benefit in the way that Andr s and I have. I suspect that there are other careers waiting to be made with this dataset and I m excited by the prospect of watching those careers develop.
You can find out more about the dataset, and how to apply for access, by reading the data descriptor on Nature s website.
As children use digital media to learn and socialize, others are collecting and analyzing data about these activities. In school and at play, these children find that they are the subjects of data science. As believers in the power of data analysis, we believe that this approach falls short of data science s potential to promote innovation, learning, and power.
Motivated by this fact, we have been working over the last three years as part of a team at the MIT Media Lab and the University of Washington to design and build a system that attempts to support an alternative vision: children as data scientists. The system we have built is described in a new paper Scratch Community Blocks: Supporting Children as Data Scientists that will be published in the proceedings of CHI 2017.
Our system is built on top of Scratch, a visual, block-based programming language designed for children and youth. Scratch is also an online community with over 15 million registered members who share their Scratch projects, remix each others work, have conversations, provide feedback, bookmark or love projects they like, follow other users, and more. Over the last decade, researchers including us have used the Scratch online community s database to study the youth using Scratch. With Scratch Community Blocks, we attempt to put the power to programmatically analyze these data into the hands of the users themselves.
To do so, our new system adds a set of new programming primitives (blocks) to Scratch so that users can access public data from the Scratch website from inside Scratch. Blocks in the new system gives users access to project and user metadata, information about social interaction, and data about what types of code are used in projects. The full palette of blocks to access different categories of data is shown below.
Project metadataUser metadataSite-wide statistics
The new blocks allow users to programmatically access, filter, and analyze data about their own participation in the community. For example, with the simple script below, we can find whether we have followers in Scratch who report themselves to be from Spain, and what their usernames are.
Simple demonstration of Scratch Community Blocks
In designing the system, we had two primary motivations. First, we wanted to support avenues through which children can engage in curiosity-driven, creative explorations of public Scratch data. Second, we wanted to foster self-reflection with data. As children looked back upon their own participation and coding activity in Scratch through the project they and their peers made, we wanted them to reflect on their own behavior and learning in ways that shaped their future behavior and promoted exploration.
After designing and building the system over 2014 and 2015, we invited a group of active Scratch users to beta test the system in early 2016. Over four months, 700 users created more than 1,600 projects. The diversity and depth of users creativity with the new blocks surprised us. Children created projects that gave the viewer of the project a personalized doughnut-chart visualization of their coding vocabulary on Scratch, rendered the viewer s number of followers as scoops of ice-cream on a cone, attempted to find whether love-its for projects are more common on Scratch than favorites , and told users how talkative they were by counting the cumulative string-length of project titles and descriptions.
We found that children, rather than making canonical visualizations such as pie-charts or bar-graphs, frequently made information representations that spoke to their own identities and aesthetic sensibilities. A 13-year-old girl had made a virtual doll dress-up game where the player s ability to buy virtual clothes and accessories for the doll was determined by the level of their activity in the Scratch community. When we asked about her motivation for making such a project, she said:
I was trying to think of something that somebody hadn t done yet, and I didn t see that. And also I really like to do art on Scratch and that was a good opportunity to use that and mix the two [art and data] together.
We also found at least some evidence that the system supported self-reflection with data. For example, after seeing a project that showed its viewers a visualization of their past coding vocabulary, a 15-year-old realized that he does not do much programming with the pen-related primitives in Scratch, and wrote in a comment, epic! looks like we need to use more pen blocks. :D.
Doughnut visualizationIce-cream visualizationData-driven doll dress up
Additionally, we noted that that as children made and interacted with projects made with Scratch Community Blocks, they started to critically think about the implications of data collection and analysis. These conversations are the subject of another paper (also being published in CHI 2017).
In a 1971 article called Teaching Children to be Mathematicians vs. Teaching About Mathematics , Seymour Papert argued for the need for children doing mathematics vs. learning about it. He showed how Logo, the programming language he was developing at that time with his colleagues, could offer children a space to use and engage with mathematical ideas in creative and personally motivated ways. This, he argued, enabled children to go beyond knowing about mathematics to doing mathematics, as a mathematician would.
Scratch Community Blocks has not yet been launched for all Scratch users and has several important limitations we discuss in the paper. That said, we feel that the projects created by children in our the beta test demonstrate the real potential for children to do data science, and not just know about it, provide data for it, and to have their behavior nudged and shaped by it.
This blog post and the paper it describes are collaborative work with Sayamindu Dasgupta. We have also received support and feedback from members of the Scratch team at MIT (especially Mitch Resnick and Natalie Rusk), as well as from Hal Abelson. Financial support came from the US National Science Foundation. The paper itself is open access so anyone can read the entire paper here. This blog post was also posted on Sayamindu Dasgupta s blog, on the Community Data Science Collective blog, and in several other places.
Like I wrote before, we at Collabora have been working on improving WebKitGTK+ performance for customer projects, such as Apertis. We took the opportunity brought by recent improvements to WebKitGTK+ and GTK+ itself to make the final leg of drawing contents to screen as efficient as possible. And then we went on investigating why so much CPU was still being used in some of our test cases.
The first weird thing we noticed is performance was actually degraded on Wayland compared to running under X11. After some investigation we found a lot of time was being spent inside GTK+, painting the window s background.
Here s the thing: the problem only showed under Wayland because in that case GTK+ is responsible for painting the window decorations, whereas in the X11 case the window manager does it. That means all of that expensive blurring and rendering of shadows fell on GTK+ s lap.
During the web engines hackfest, a couple of months ago, I delved deeper into the problem and noticed, with Carlos Garcia s help, that it was even worse when HiDPI displays were thrown into the mix. The scaling made things unbearably slower.
You might also be wondering why would painting of window decorations be such a problem, anyway? They should only be repainted when a window changes size or state anyway, which should be pretty rare, right? Right, that is one of the reasons why we had to make it fast, though: the resizing experience was pretty terrible. But we ll get back to that later.
So I dug into that, made a few tries at understanding the issue and came up with a patch showing how applying the blur was being way too expensive. After a bit of discussion with our own Pekka Paalanen and Benjamin Otte we found the root cause: a fast path was not being hit by pixman due to the difference in scale factors on the shadow mask and the target surface. We made the shadow mask scale the same as the surface s and voil , sane performance.
I keep talking about this being a performance problem, but how bad was it? In the following video you can see how huge the impact in performance of this problem was on my very recent laptop with a HiDPI display. The video starts with an Epiphany window running with a patched GTK+ showing a nice demo the WebKit folks cooked for CSS animations and 3D transforms.
After a few seconds I quickly alt-tab to the version running with unpatched GTK+ I made the window the exact size and position of the other one, so that it is under the same conditions and the difference can be seen more easily. It is massive.
Yes, all of that slow down was caused by repainting window shadows! OK, so that solved the problem for HiDPI displays, made resizing saner, great! But why is GTK+ repainting the window even if only the contents are changing, anyway? Well, that turned out to be an off-by-one bug in the code that checks whether the invalidated area includes part of the window decorations.
If the area being changed spanned the whole window width, say, it would always cause the shadows to be repainted. By fixing that, we now avoid all of the shadow drawing code when we are running full-window animations such as the CSS poster circle or gtk3-demo s pixbufs demo.
As you can see in the video below, the gtk3-demo running with the patched GTK+ (the one on the right) is using a lot less CPU and has smoother animation than the one running with the unpatched GTK+ (left).
Pretty much all of the overhead caused by window decorations is gone in the patched version. It is still using quite a bit of CPU to animate those pixbufs, though, so some work still remains. Also, the overhead added to integrate cairo and GL rendering in GTK+ is pretty significant in the WebKitGTK+ CSS animation case. Hopefully that ll get much better from GTK+ 4 onwards.
Earlier this week, I finally got my new machine that came with my new position at the University of Pennsylvania: A shiny Thinkpad T460s that now replaces my T430s. (Yes, there is a pattern. It continues with T400 and T41p.) I decided to re-install my Debian system from scratch and copy over only the home directory a bit of purification does not hurt. This blog post contains some random notes that might be useful to someone or alternative where I hope someone can tell me how to fix and improve things.
Installation
The installation (using debian-installer from a USB drive) went mostly smooth, including LVM on an encrypted partition. Unfortunately, it did not set up grub correctly for the UEFI system to boot, so I had to jump through some hoops (using the grub on the USB drive to manually boot into the installed system, and installing grub-efi from there) until the system actually came up.
High-resolution display
This laptop has a 2560 1440 high resolution display. Modern desktop environments like GNOME supposedly handle that quite nicely, but for reasons explained in an earlier post, I do not use a desktop envrionment but have a minimalistic setup based on Xmonad. I managed to get a decent setup now, by turning lots of manual knobs:
For the linux console, setting
FONTFACE="Terminus"
FONTSIZE="12x24"
in /etc/default/console-setup yielded good results.
For the few GTK-2 applications that I am still running, I set
gtk-font-name="Sans 16"
in ~/.gtkrc-2.0. Similarly, for GTK-3 I have
[Settings]
gtk-font-name = Sans 16
in ~/.config/gtk-3.0/settings.ini.
Programs like gnome-terminal, Evolution and hexchat refer to the System default document font and System default monospace font . I remember that it was possible to configure these in the GNOME control center, but I could not find any way of configuring these using command line tools, so I resorted to manually setting the font for these. With the help from Alexandre Franke I figured out that the magic incarnation here is:
gsettings set org.gnome.desktop.interface monospace-font-name 'Monospace 16'
gsettings set org.gnome.desktop.interface document-font-name 'Serif 16'
gsettings set org.gnome.desktop.interface font-name 'Sans 16'
Firefox seemed to have picked up these settings for the UI, so that was good. To make web pages readable, I set layout.css.devPixelsPerPx to 1.5 in about:config.
GVim has set guifont=Monospace\ 16 in ~/.vimrc. The toolbar is tiny, but I hardly use it anyways.
Setting the font of Xmonad prompts requires the sytax
, font = "xft:Sans:size=16"
Speaking about Xmonad prompts: Check out the XMonad.Prompt.Unicode module that I have been using for years and recently submitted upstream.
I launch Chromium (or rather the desktop applications that I use that happen to be Chrome apps) with the parameter --force-device-scale-factor=1.5.
Libreoffice seems to be best configured by running xrandr --dpi 194 before hand. This seems also to be read by Firefox, doubling the effect of the font size in the gtk settings, which is annoying. Luckily I do not work with Libreoffice often, so for now I ll just set that manually when needed.
I am not quite satisfied. I have the impression that the 16 point size font, e.g. in Evolution, is not really pretty, so I am happy to take suggestions here.
I found the ArchWiki page on HiDPI very useful here.
Trackpoint and Touchpad
One reason for me to sticking with Thinkpads is their trackpoint, which I use exclusively. In previous models, I disabled the touchpad in the BIOS, but this did not seem to have an effect here, so I added the following section to /etc/X11/xorg.conf.d/30-touchpad.conf
At one point I left out the MatchProduct line, disabling all input in the X server. Had to boot into recovery mode to fix that.
Unfortunately, there is something wrong with the trackpoint and the buttons: When I am moving the trackpoint (and maybe if there is actual load on the machine), mouse button press and release events sometimes get lost. This is quite annoying I try to open a folder in Evolution and accidentially move it.
I installed the latest Kernel from Debian experimental (4.8.0-rc8), but it did not help.
I filed a bug report against libinput although I am not fully sure that that s the culprit.
Update: According to Benjamin Tissoires it is a known firmware bug and the appropriate people are working on a work-around. Until then I am advised to keep my palm of the touchpad.
Also, I found the trackpoint too slow. I am not sure if it is simply because of the large resolution of the screen, or because some movement events are also swallowed. For now, I simply changed the speed by writing
Brightness control
The system would not automatically react to pressing Fn-F5 and Fn-F6, which are the keys to adjust the brightness. I am unsure about how and by what software component it should be handled, but the solution that I found was to set
The T460s does not actually have a sleep button, that line is a reminiscence from my T430s. I suspend the machine by pressing the power button now, thanks to HandlePowerKey=suspend in /etc/systemd/logind.conf.
Profile Weirdness
Something strange happend to my environment variables after the move. It is clearly not hardware related, but I simply cannot explain what has changed: All relevant files in /etc look similar enough.
I use ~/.profile to extend the PATH and set some other variables. Previously, these settings were in effect in my whole X session, which is started by lightdm with auto-login, followed by xmonad-session. I could find no better way to fix that than stating . ~/.profile early in my ~/.xmonad/xmonad-session-rc. Very strange.
With more than 10 million users, the Scratch online community is the largest online community where kids learn to program. Since it was created, a central goal of the community has been to promote remixing the reworking and recombination of existing creative artifacts. As the video above shows, remixing programming projects in the current web-based version of Scratch is as easy is as clicking on the see inside button in a project web-page, and then clicking on the remix button in the web-based code editor. Today, close to 30% of projects on Scratch are remixes.
Remixing plays such a central role in Scratch because its designers believed that remixing can play an important role in learning. After all, Scratch was designed first and foremost as a learning community with its roots in the Constructionist framework developed at MIT by Seymour Papert and his colleagues. The design of the Scratch online community was inspired by Papert s vision of a learning community similar to Brazilian Samba schools (Henry Jenkins writes about his experience of Samba schools in the context of Papert s vision here), and a comment Marvin Minsky made in 1984:
Adults worry a lot these days. Especially, they worry about how to make other people learn more about computers. They want to make us all computer-literate. Literacy means both reading and writing, but most books and courses about computers only tell you about writing programs. Worse, they only tell about commands and instructions and programming-language grammar rules. They hardly ever give examples. But real languages are more than words and grammar rules. There s also literature what people use the language for. No one ever learns a language from being told its grammar rules. We always start with stories about things that interest us.
In a new paper titled Remixing as a pathway to Computational Thinking that was recently published at the ACM Conference on Computer Supported Collaborative Work and Social Computing (CSCW) conference, we used a series of quantitative measures of online behavior to try to uncover evidence that might support the theory that remixing in Scratch is positively associated with learning.
Of course, because Scratch is an informal environment with no set path for users, no lesson plan, and no quizzes, measuring learning is an open problem. In our study, we built on two different approaches to measure learning in Scratch. The first approach considers the number of distinct types of programming blocks available in Scratch that a user has used over her lifetime in Scratch (there are 120 in total) something that can be thought of as a block repertoire or vocabulary. This measure has been used to model informal learning in Scratch in an earlier study. Using this approach, we hypothesized that users who remix more will have a faster rate of growth for their code vocabulary.
Controlling for a number of factors (e.g. age of user, the general level of activity) we found evidence of a small, but positive relationship between the number of remixes a user has shared and her block vocabulary as measured by the unique blocks she used in her non-remix projects. Intriguingly, we also found a strong association between the number of downloads by a user and her vocabulary growth. One interpretation is that this learning might also be associated with less active forms of appropriation, like the process of reading source code described by Minksy.
The second approach we used considered specific concepts in programming, such as loops, or event-handling. To measure this, we utilized a mapping of Scratch blocks to key programming concepts found in this paper by Karen Brennan and Mitchel Resnick. For example, in the image below are all the Scratch blocks mapped to the concept of loop .
We looked at six concepts in total (conditionals, data, events, loops, operators, and parallelism). In each case, we hypothesized that if someone has had never used a given concept before, they would be more likely to use that concept after encountering it while remixing an existing project.
Using this second approach, we found that users who had never used a concept were more likely to do so if they had been exposed to the concept through remixing. Although some concepts were more widely used than others, we found a positive relationship between concept use and exposure through remixing for each of the six concepts. We found that this relationship was true even if we ignored obvious examples of cutting and pasting of blocks of code. In all of these models, we found what we believe is evidence of learning through remixing.
Of course, there are many limitations in this work. What we found are all positive correlations we do not know if these relationships are causal. Moreover, our measures do not really tell us whether someone has understood the usage of a given block or programming concept.However, even with these limitations, we are excited by the results of our work, and we plan to build on what we have. Our next steps include developing and utilizing better measures of learning, as well as looking at other methods of appropriation like viewing the source code of a project.
As some of the world knows full well by now, I've been noodling with Go
for a few years, working through its pros, its cons, and thinking a lot
about how humans use code to express thoughts and ideas. Go's got a lot of
neat use cases, suited to particular problems, and used in the right place,
you can see some clear massive wins.
I've started writing Debian tooling in Go, because it's a pretty natural fit.
Go's fairly tight, and overhead shouldn't be taken up by your operating system.
After a while, I wound up hitting the usual blockers, and started to build up
abstractions. They became pretty darn useful, so, this blog post is announcing
(a still incomplete, year old and perhaps API changing) Debian package for Go.
The Go importable name is pault.ag/go/debian. This contains a lot of utilities
for dealing with Debian packages, and will become an edited down "toolbelt"
for working with or on Debian packages.
Module Overview
Currently, the package contains 4 major sub packages. They're a changelog
parser, a control file parser, deb file format parser, dependency parser
and a version parser. Together, these are a set of powerful building blocks
which can be used together to create higher order systems with reliable
understandings of the world.
changelog
The first (and perhaps most incomplete and least tested) is a changelog file
parser.. This provides the
programmer with the ability to pull out the suite being targeted in the
changelog, when each upload was, and the version for each. For example, let's
look at how we can pull when all the uploads of Docker to sid took place:
funcmain()resp,err:=http.Get("http://metadata.ftp-master.debian.org/changelogs/main/d/docker.io/unstable_changelog")iferr!=nilpanic(err)allEntries,err:=changelog.Parse(resp.Body)iferr!=nilpanic(err)for_,entry:=rangeallEntriesfmt.Printf("Version %s was uploaded on %s\n",entry.Version,entry.When)
The output of which looks like:
Version 1.8.3~ds1-2 was uploaded on 2015-11-04 00:09:02 -0800 -0800
Version 1.8.3~ds1-1 was uploaded on 2015-10-29 19:40:51 -0700 -0700
Version 1.8.2~ds1-2 was uploaded on 2015-10-29 07:23:10 -0700 -0700
Version 1.8.2~ds1-1 was uploaded on 2015-10-28 14:21:00 -0700 -0700
Version 1.7.1~dfsg1-1 was uploaded on 2015-08-26 10:13:48 -0700 -0700
Version 1.6.2~dfsg1-2 was uploaded on 2015-07-01 07:45:19 -0600 -0600
Version 1.6.2~dfsg1-1 was uploaded on 2015-05-21 00:47:43 -0600 -0600
Version 1.6.1+dfsg1-2 was uploaded on 2015-05-10 13:02:54 -0400 EDT
Version 1.6.1+dfsg1-1 was uploaded on 2015-05-08 17:57:10 -0600 -0600
Version 1.6.0+dfsg1-1 was uploaded on 2015-05-05 15:10:49 -0600 -0600
Version 1.6.0+dfsg1-1~exp1 was uploaded on 2015-04-16 18:00:21 -0600 -0600
Version 1.6.0~rc7~dfsg1-1~exp1 was uploaded on 2015-04-15 19:35:46 -0600 -0600
Version 1.6.0~rc4~dfsg1-1 was uploaded on 2015-04-06 17:11:33 -0600 -0600
Version 1.5.0~dfsg1-1 was uploaded on 2015-03-10 22:58:49 -0600 -0600
Version 1.3.3~dfsg1-2 was uploaded on 2015-01-03 00:11:47 -0700 -0700
Version 1.3.3~dfsg1-1 was uploaded on 2014-12-18 21:54:12 -0700 -0700
Version 1.3.2~dfsg1-1 was uploaded on 2014-11-24 19:14:28 -0500 EST
Version 1.3.1~dfsg1-2 was uploaded on 2014-11-07 13:11:34 -0700 -0700
Version 1.3.1~dfsg1-1 was uploaded on 2014-11-03 08:26:29 -0700 -0700
Version 1.3.0~dfsg1-1 was uploaded on 2014-10-17 00:56:07 -0600 -0600
Version 1.2.0~dfsg1-2 was uploaded on 2014-10-09 00:08:11 +0000 +0000
Version 1.2.0~dfsg1-1 was uploaded on 2014-09-13 11:43:17 -0600 -0600
Version 1.0.0~dfsg1-1 was uploaded on 2014-06-13 21:04:53 -0400 EDT
Version 0.11.1~dfsg1-1 was uploaded on 2014-05-09 17:30:45 -0400 EDT
Version 0.9.1~dfsg1-2 was uploaded on 2014-04-08 23:19:08 -0400 EDT
Version 0.9.1~dfsg1-1 was uploaded on 2014-04-03 21:38:30 -0400 EDT
Version 0.9.0+dfsg1-1 was uploaded on 2014-03-11 22:24:31 -0400 EDT
Version 0.8.1+dfsg1-1 was uploaded on 2014-02-25 20:56:31 -0500 EST
Version 0.8.0+dfsg1-2 was uploaded on 2014-02-15 17:51:58 -0500 EST
Version 0.8.0+dfsg1-1 was uploaded on 2014-02-10 20:41:10 -0500 EST
Version 0.7.6+dfsg1-1 was uploaded on 2014-01-22 22:50:47 -0500 EST
Version 0.7.1+dfsg1-1 was uploaded on 2014-01-15 20:22:34 -0500 EST
Version 0.6.7+dfsg1-3 was uploaded on 2014-01-09 20:10:20 -0500 EST
Version 0.6.7+dfsg1-2 was uploaded on 2014-01-08 19:14:02 -0500 EST
Version 0.6.7+dfsg1-1 was uploaded on 2014-01-07 21:06:10 -0500 EST
control
Next is one of the most complex, and one of the oldest parts of go-debian,
which is the control file parser
(otherwise sometimes known as deb822). This module was inspired by the way
that the json module works in Go, allowing for files to be defined in code
with a struct. This tends to be a bit more declarative, but also winds up
putting logic into struct tags, which can be a nasty anti-pattern if used too
much.
The first primitive in this module is the concept of a Paragraph, a struct
containing two values, the order of keys seen, and a map of string to string.
All higher order functions dealing with control files will go through this
type, which is a helpful interchange format to be aware of. All parsing of
meaning from the Control file happens when the Paragraph is unpacked into
a struct using reflection.
The idea behind this strategy that you define your struct, and let the Control
parser handle unpacking the data from the IO into your container, letting you
maintain type safety, since you never have to read and cast, the conversion
will handle this, and return an Unmarshaling error in the event of failure.
Additionally, Structs that define an anonymous member of control.Paragraph
will have the raw Paragraph struct of the underlying file, allowing the
programmer to handle dynamic tags (such as X-Foo), or at least, letting
them survive the round-trip through go.
The default decoder
contains an argument, the ability to verify the input control file using an
OpenPGP keyring, which is exposed to the programmer through the
(*Decoder).Signer() function. If the passed argument is nil, it will not
check the input file signature (at all!), and if it has been passed, any
signed data must be found or an error will fall out of the NewDecoder call.
On the way out, the opposite happens, where the struct is introspected,
turned into a control.Paragraph, and then written out to the io.Writer.
Here's a quick (and VERY dirty) example showing the basics of reading and
writing Debian Control files with go-debian.
packagemainimport("fmt""io""net/http""strings""pault.ag/go/debian/control")typeAllowedPackagestructPackagestringFingerprintstringfunc(a*AllowedPackage)UnmarshalControl(instring)errorin=strings.TrimSpace(in)chunks:=strings.SplitN(in," ",2)iflen(chunks)!=2returnfmt.Errorf("Syntax sucks: '%s'",in)a.Package=chunks[0]a.Fingerprint=chunks[1][1:len(chunks[1])-1]returnniltypeDMUAstructFingerprintstringUidstringAllowedPackages[]AllowedPackage control:"Allow" delim:"," funcmain()resp,err:=http.Get("http://metadata.ftp-master.debian.org/dm.txt")iferr!=nilpanic(err)decoder,err:=control.NewDecoder(resp.Body,nil)iferr!=nilpanic(err)fordmua:=DMUAiferr:=decoder.Decode(&dmua);err!=niliferr==io.EOFbreakpanic(err)fmt.Printf("The DM %s is allowed to upload:\n",dmua.Uid)for_,allowedPackage:=rangedmua.AllowedPackagesfmt.Printf(" %s [granted by %s]\n",allowedPackage.Package,allowedPackage.Fingerprint)
Output (truncated!) looks a bit like:
...
The DM Allison Randal <allison@lohutok.net> is allowed to upload:
parrot [granted by A4F455C3414B10563FCC9244AFA51BD6CDE573CB]
...
The DM Benjamin Barenblat <bbaren@mit.edu> is allowed to upload:
boogie [granted by 3224C4469D7DF8F3D6F41A02BBC756DDBE595F6B]
dafny [granted by 3224C4469D7DF8F3D6F41A02BBC756DDBE595F6B]
transmission-remote-gtk [granted by 3224C4469D7DF8F3D6F41A02BBC756DDBE595F6B]
urweb [granted by 3224C4469D7DF8F3D6F41A02BBC756DDBE595F6B]
...
The DM <aelmahmoudy@sabily.org> is allowed to upload:
covered [granted by 41352A3B4726ACC590940097F0A98A4C4CD6E3D2]
dico [granted by 6ADD5093AC6D1072C9129000B1CCD97290267086]
drawtiming [granted by 41352A3B4726ACC590940097F0A98A4C4CD6E3D2]
fonts-hosny-amiri [granted by BD838A2BAAF9E3408BD9646833BE1A0A8C2ED8FF]
...
...
deb
Next up, we've got the deb module. This contains code to handle reading
Debian 2.0 .deb files. It contains a wrapper that will parse the control
member, and provide the data member through the
archive/tar interface.
Here's an example of how to read a .deb file, access some metadata, and
iterate over the tar archive, and print the filenames of each of the
entries.
dependency
The dependency package provides an interface to parse and compute
dependencies. This package is a bit odd in that, well, there's no other
library that does this. The issue is that there are actually two different
parsers that compute our Dependency lines, one in Perl (as part of dpkg-dev)
and another in C (in dpkg).
To date, this has resulted in me filing
threedifferentbugs.
I also found a broken package in the
archive,
which actually resulted in another bug being (totally accidentally)
already fixed.
I hope to continue to run the archive through my parser in hopes of finding
more bugs! This package is a bit complex, but it basically just returns what
amounts to be an AST
for our Dependency lines. I'm positive there are bugs, so file them!
funcmain()dep,err:=dependency.Parse("foo bar, baz, foobar [amd64] bazfoo [!sparc], fnord:armhf [gnu-linux-sparc]")iferr!=nilpanic(err)anySparc,err:=dependency.ParseArch("sparc")iferr!=nilpanic(err)for_,possi:=rangedep.GetPossibilities(*anySparc)fmt.Printf("%s (%s)\n",possi.Name,possi.Arch)
Gives the output:
foo (<nil>)
baz (<nil>)
fnord (armhf)
version
Right off the bat, I'd like to thank
Michael Stapelberg for letting me graft this
out of dcs and into the go-debian package.
This was nearly entirely his work (with a one or two line function I added
later), and was amazingly helpful to have. Thank you!
This module implements Debian version comparisons and parsing, allowing for
sorting in lists, checking to see if it's native or not, and letting the
programmer to implement smart(er!) logic based on upstream (or Debian)
version numbers.
This module is extremely easy to use and very straightforward, and not worth
writing an example for.
Final thoughts
This is more of a "Yeah, OK, this has been useful enough to me at this point
that I'm going to support this" rather than a "It's stable!" or even
"It's alive!" post. Hopefully folks can report bugs and help iterate on
this module until we have some really clean building blocks to build
solid higher level systems on top of. Being able to have multiple libraries
interoperate by relying on go-debian will be a massive ease.
I'm in need of more documentation, and to finalize some parts of the older
sub package APIs, but I'm hoping to be at a "1.0" real soon now.
As a rule, I avoid writing publicly on political topics, but I m making an exception.
In case you haven t been following it, the senior Republican and the senior Democrat on the Senate Intelligence Committee recently announced a legislative proposal misleadingly called the Compliance with Court Orders Act of 2016. The full text of the draft can be found here. It would effectively ban devices and software in the United States that the manufacturer cannot retrieve data from. Here is a good analysis of the breadth of the proposal and a good analysis of the bill itself.
While complying with court orders might sound great in theory, in practice this means these devices and software will be insecure by design. While that s probably reasonably obvious to most normal readers here, don t just take my word for it, take Bruce Schneier s.
In my opinion, policy makers (and it s not just in the United States) are suffering from a perception gap about security and how technically hard it is to get right. It seems to me that they are convinced that technologists could just do security right while still allowing some level of extraordinary access for law enforcement if they only wanted to. We ve tried this before and the story never seems to end well. This isn t a complaint from wide eyed radicals that such extraordinary access is morally wrong or inappropriate. It s hard core technologists saying it can t be done.
I don t know how to get the message across. Here s President Obama, in my opinion, completely missing the point when he equates a desire for security with fetishizing our phones above every other value. Here are some very smart people trying very hard to be reasonable about some mythical middle ground. As Riana Pfefferkorn s analysis that I linked in the first paragraph discusses, this middle ground doesn t exist and all the arm waving in the world by policy makers won t create it.
Coincidentally, this same week, the White House announced a new Commission on Enhancing National Cybersecurity . Cybersecurity is certainly something we could use more of, unfortunately Congress seems to be heading off in the opposite direction and no one from the executive branch has spoken out against it.
Security and privacy are important to many people. Given the personal and financial importance of data stored in computers (traditional or mobile), users don t want criminals to get a hold of it. Companies know this, which is why both Apple IOS and Google Android both encrypt their local file systems by default now. If a bill anything like what s been proposed becomes law, users that care about security are going to go elsewhere. That may end up being non-US companies products or US companies may shift operations to localities more friendly to secure design. Either way, the US tech sector loses. A more accurate title would have been Technology Jobs Off-Shoring Act of 2016.
EDIT: Fixed a typo.
Started in 2008, lldpd is an implementation of
IEEE 802.1AB-2005 (aka LLDP) written in C. While it contains some
unit tests, like many other network-related software at the time, the
coverage of those is pretty poor: they are hard to write because the
code is written in an imperative style and tighly coupled with the
system. It would require extensive mocking1. While a rewrite
(complete or iterative) would help to make the code more
test-friendly, it would be quite an effort and it will likely
introduce operational bugs along the way.
To get better test coverage, the major features of lldpd are now
verified through integration tests. Those tests leverage Linux
network namespaces to setup a lightweight and isolated environment
for each test. They run through pytest, a powerful testing tool.
pytest in a nutshell
pytest is a Python testing tool whose primary use is to write
tests for Python applications but is versatile enough for other
creative usages. It is bundled with three killer features:
you can directly use the assert keyword,
you can inject fixtures in any test function, and
you can parametrize tests.
Assertions
With unittest, the unit testing framework included with Python,
and many similar frameworks, unit tests have to be encapsulated into a
class and use the provided assertion methods. For example:
The equivalent with pytest is simpler and more readable:
deftest_addition():assert1+3==4
pytest will analyze the AST and display useful error messages in
case of failure. For further information, see
Benjamin Peterson s article.
Fixtures
A fixture is the set of actions performed in order to prepare the
system to run some tests. With classic frameworks, you can only
define one fixture for a set of tests:
In the example above, we want to test various commands on a remote
VM. The fixture launches a new VM and configure an SSH
connection. However, if the SSH connection cannot be established, the
fixture will fail and the tearDown() method won t be invoked. The VM
will be left running.
Instead, with pytest, we could do this:
The first fixture will provide a freshly booted VM. The second one
will setup an SSH connection to the VM provided as an
argument. Fixtures are used through dependency injection: just
give their names in the signature of the test functions and fixtures
that need them. Each fixture only handle the lifetime of one
entity. Whatever a dependent test function or fixture succeeds or
fails, the VM will always be finally destroyed.
Parameters
If you want to run the same test several times with a varying
parameter, you can dynamically create test functions or use one test
function with a loop. With pytest, you can parametrize test
functions and fixtures:
First, the test will be executed only if lldpd was compiled with
LLDP-MED support. Second, the test is parametrized. We will execute
four distinct tests, one for each role that lldpd should be able to
take as an LLDP-MED-enabled endpoint.
The signature of the test has four parameters that are not covered by
the parametrize() decorator: lldpd, lldpcli, namespaces and
links. They are fixtures. A lot of magic happen in those to keep
the actual tests short:
lldpd is a factory to spawn an instance of lldpd. When called,
it will setup the current namespace (setting up the chroot,
creating the user and group for privilege separation, replacing
some files to be distribution-agnostic, ), then call lldpd
with the additional parameters provided. The output is recorded and
added to the test report in case of failure. The module also
contains the creation of the pytest.config.lldpd object that is
used to record the features supported by lldpd and skip
non-matching tests. You can read
fixtures/programs.py for more details.
lldpcli is also a factory, but it spawns instances of lldpcli,
the client to query lldpd. Moreover, it will parse the output in
a dictionary to reduce boilerplate.
namespaces is one of the most interesting pieces. It is a
factory for Linux namespaces. It will spawn a new namespace or
refer to an existing one. It is possible to switch from one namespace
to another (with with) as they are contexts. Behind the scene,
the factory maintains the appropriate file descriptors for each
namespace and switch to them with setns(). Once the test is done,
everything is wipped out as the file descriptors are garbage
collected. You can read fixtures/namespaces.py
for more details. It is quite reusable in other
projects2.
links contains helpers to handle network interfaces: creation of
virtual ethernet link between namespaces, creation of bridges,
bonds and VLAN, etc. It relies on the pyroute2 module. You can
read fixtures/network.py for more details.
You can see an example of a test run on the
Travis build for 0.9.2. Since each test is correctly isolated,
it s possible to run parallel tests with pytest -n 10 --boxed. To
catch even more bugs, both the address sanitizer (ASAN) and the
undefined behavior sanitizer (UBSAN) are enabled. In case of a
problem, notably a memory leak, the faulty program will exit with a
non-zero exit code and the associated test will fail.
A project like cwrap would definitely help. However, it
lacks support for Netlink and raw sockets that are essential
in lldpd operations.
There are three main limitations in the use of
namespaces with this fixture. First, when creating a
user namespace, only root is mapped to the current
user. With lldpd, we have two users (root and
_lldpd). Therefore, the tests have to run as root.
The second limitation is with the PID namespace. It s
not possible for a process to switch from one PID
namespace to another. When you call setns() on a PID
namespace, only children of the current process will
be in the new PID namespace. The PID namespace is
convenient to ensure everyone gets killed once the
tests are terminated but you must keep in mind that
/proc must be mounted in children only. The third
limitation is that, for some namespaces (PID and
user), all threads of a process must be part of the
same namespace. Therefore, don t use threads in
tests. Use multiprocessing module instead.
Unfortunately, a series of recent legal rulings have forced us to suspend our campaign. In 2015, Time Warner s copyright claim to Happy Birthday was declared invalid. In 2016, a settlement was announced that calls for a judge to officially declare that the song is in the public domain.
This is horrible news for the future of music. It is horrible news for anybody who cares that creators, their heirs, etc., are fairly remunerated when their work is performed. What incentive will there be for anybody to pen the next Happy Birthday knowing that less than a century after their deaths their estates and the large multinational companies that buy their estates might not be able to reap the financial rewards from their hard work and creativity?
We are currently planning a campaign to push for a retroactive extension of copyright law to place Happy Birthday, and other works, back into the private domain where they belong! We believe this is a winnable fight. After all, copyright has been retroactively extended before! Stay tuned! In the meantime, we ll keep this page here for historical purposes.
My office door is on the second floor in front the major staircase in my building. I work with my door open so that my colleagues and my students know when I m in. The only time I consider deviating from this policy is the first week of the quarter when I m faced with a stream of students, usually lost on their way to class and that, embarrassingly, I am usually unable to help.
I made this poster so that these conversations can, in a way, continue even when I am not in the office.
What happened in the reproducible
builds effort between January 10th and January 16th:
Toolchain fixes
Benjamin Drung uploaded mozilla-devscripts/0.43 which sorts the file list in preferences files. Original patch by Reiner Herrmann.
Lunar submitted an updated patch series to make timestamps in packages created by dpkg deterministic. To ensure that the mtimes in data.tar are reproducible, with the patches, dpkg-deb uses the --clamp-mtime option added in tar/1.28-1 when available. An updated package has been uploaded to the experimental repository. This removed the need for a modified debhelper as all required changes for reproducibility have been merged or are now covered by dpkg.
reproducible.debian.net
Once again, Vagrant Cascadian is providing another armhf build system, allowing to run 6 more armhf builder jobs, right there. (h01ger)
Stop requiring a modified debhelper and adapt to the latest dpkg experimental version by providing a predetermined identifier for the .buildinfo filename. (Mattia Rizzolo, h01ger)
New X.509 certificates were set up for jenkins.debian.net and reproducible.debian.net using Let's Encrypt!. Thanks to GlobalSign for providing certificates for the last year free of charge. (h01ger)
Package reviews
131 reviews have been removed, 85 added and 32 updated in the previous week.
FTBFS issues filled: 29. Thanks to Chris Lamb, Mattia Rizzolo, and Niko Tyni.
New issue identified: timestamps_in_manpages_added_by_golang_cobra.
We invite you to celebrate the life and activism efforts of Aaron Swartz, hosted by UW Communication professor Benjamin Mako Hill. The event is next week and will consist of a short book reading, a screening of a documentary about Aaron s life, and a Q&A with Mako who knew Aaron well details are below. No RSVP required; we hope you can join us.
Aaron Swartz was a programming prodigy, entrepreneur, and information activist who contributed to the core Internet protocol RSS and co-founded Reddit, among other groundbreaking work. However, it was his efforts in social justice and political organizing combined with his aggressive approach to promoting increased access to information that entangled him in a two-year legal nightmare that ended with the taking of his own life at the age of 26.
January 11, 2016 marks the third anniversary of his death. Join us two days later for a reading from a new posthumous collection of Swartz s writing published by New Press, a showing of The Internet s Own Boy (a documentary about his life), and a Q&A with UW Communication professor Benjamin Mako Hill a former roommate and friend of Swartz and a contributor to and co-editor of the first section of the new book.
If you re not in Seattle, there are events with similar programs being organized in Atlanta, Chicago, Dallas, New York, and San Francisco. All of these other events will be on Monday January 11 and registration is required for all of them. I will be speaking at the event in San Francisco.
The New Press has published a new collection of Aaron Swartz s writing called The Boy Who Could Change the World: The Writings of Aaron Swartz. I worked with Seth Schoen to introduce and help edit the opening section of book that includes Aaron s writings on free culture, access to information and knowledge, and copyright. Seth and I have put our introduction online under an appropriately free license (CC BY-SA).
Over the last week, I ve read the whole book again. I think the book really is a wonderful snapshot of Aaron s thought and personality. It s got bits that make me roll my eyes, bits that make me want to shout in support, and bits that continue to challenge me. It all makes me miss Aaron terribly. I strongly recommend the book.
Because the publication is post-humous, it s meant that folks like me are doing media work for the book. In honor of naming the book their progressive pick of the week, Truthout has also published an interview with me about Aaron and the book.
Other folks who introduced and/or edited topical sections in the book are David Auerbach (Computers), David Segal (Politics), Cory Doctorow (Media), James Grimmelmann (Books and Culture), and Astra Taylor (Unschool). The book is introduced by Larry Lessig.
At LibrePlanet 2015 (the FSF s annual conference), I gave a talk called Access Without Empowerment as one of the conference keynote addresses. As I did for my 2013 LibrePlanet talk, I ve edited together a version that includes the slides and I ve posted it online in WebM and on YouTube.
Here s the summary written up in the LibrePlanet program:
The free software movement has twin goals: promoting access to software through users freedom to share, and empowering users by giving them control over their technology. For all our movement s success, we have been much more successful at the former. I will use data from free software and from several related movements to explain why promoting empowerment is systematically more difficult than promoting access and I will explore how our movement might address the second challenge in the future.
(You can Follow or Tweet about this blog on Twitter)
Over the last week, people have been saying a lot about the wonderful life of Ian Murdock and his contributions to Debian and the world of free software. According to one news site, a San Francisco police officer, Grace Gatpandan, has been doing the opposite, starting a PR spin operation, leaking snippets of information about what may have happened during Ian's final 24 hours. Sadly, these things are now starting to be regurgitated without proper scrutiny by the mainstream press (note the erroneous reference to SFGate with link to SFBay.ca, this is British tabloid media at its best).
The report talks about somebody (no suggestion that it was even Ian) "trying to break into a residence". Let's translate that from the spin-doctor-speak back to English: it is the silly season, when many people have a couple of extra drinks and do silly things like losing their keys. "a residence", or just their own home perhaps? Maybe some AirBNB guest arriving late to the irritation of annoyed neighbours? Doesn't the choice of words make the motive sound so much more sinister? Nobody knows the full story and nobody knows if this was Ian, so snippets of information like this are inappropriate, especially when somebody is deceased.
Did they really mean to leave people with the impression that one of the greatest visionaries of the Linux world was also a cat burglar? That somebody who spent his life giving selflessly and generously for the benefit of the whole world (his legacy is far greater than Steve Jobs, as Debian comes with no strings attached) spends the Christmas weekend taking things from other people's houses in the dark of the night? The report doesn't mention any evidence of a break-in or any charges for breaking-in.
If having a few drinks and losing your keys in December is such a sorry state to be in, many of us could potentially be framed in the same terms at some point in our lives. That is one of the reasons I feel so compelled to write this: somebody else could be going through exactly the same experience at the moment you are reading this. Any of us could end up facing an assault as unpleasant as the tweets imply at some point in the future. At least I can console myself that as a privileged white male, the risk to myself is much lower than for those with mental illness, the homeless, transgender, Muslim or black people but as the tweets suggest, it could be any of us.
The story reports that officers didn't actually come across Ian breaking in to anything, they encountered him at a nearby street corner. If he had weapons or drugs or he was known to police that would have almost certainly been emphasized. Is it right to rush in and deprive somebody of their liberties without first giving them an opportunity to identify themselves and possibly confirm if they had a reason to be there?
The report goes on, "he was belligerent", "he became violent", "banging his head" all by himself. How often do you see intelligent and successful people like Ian Murdock spontaneously harming themselves in that way? Can you find anything like that in any of the 4,390 Ian Murdock videos on YouTube? How much more frequently do you see reports that somebody "banged their head", all by themselves of course, during some encounter with law enforcement? Do police never make mistakes like other human beings?
If any person was genuinely trying to spontaneously inflict a head injury on himself, as the police have suggested, why wouldn't the police leave them in the hospital or other suitable care? Do they really think that when people are displaying signs of self-harm, rounding them up and taking them to jail will be in their best interests?
Now, I'm not suggesting this started out with some sort of conspiracy. Police may have been at the end of a long shift (and it is a disgrace that many US police are not paid for their overtime) or just had a rough experience with somebody far more sinister. On the other hand, there may have been a mistake, gaps in police training or an inappropriate use of a procedure that is not always justified, like a strip search, that causes profound suffering for many victims.
A select number of US police forces have been shamed around the world for a series of incidents of extreme violence in recent times, including the death of Michael Brown in Ferguson, shooting Walter Scott in the back, death of Freddie Gray in Baltimore and the attempts of Chicago's police to run an on-shore version of Guantanamo Bay. Beyond those highly violent incidents, the world has also seen the abuse of Ahmed Mohamed, the Muslim schoolboy arrested for his interest in electronics and in 2013, the suicide of Aaron Swartz which appears to be a direct consequence of the "Justice" department's obsession with him.
What have the police learned from all this bad publicity? Are they changing their methods, or just hiring more spin doctors? If that is their response, then doesn't it leave them with a cruel advantage over those people who were deceased?
Isn't it standard practice for some police to simply round up anybody who is a bit lost and write up a charge sheet for resisting arrest or assaulting an officer as insurance against questions about their own excessive use of force?
When British police executed Jean Charles de Menezes on a crowded tube train and realized they had just done something incredibly outrageous, their PR office went to great lengths to try and protect their image, even photoshopping images of Menezes to make him look more like some other suspect in a wanted poster. To this day, they continue to refer to Menezes as a victim of the terrorists, could they be any more arrogant? While nobody believes the police woke up that morning thinking "let's kill some random guy on the tube", it is clear they made a mistake and like many people (not just police), they immediately prioritized protecting their reputation over protecting the truth.
Nobody else knows exactly what Ian was doing and exactly what the police did to him. We may never know. However, any disparaging or irrelevant comments from the police should be viewed with some caution.
The horrors of incarceration
It would be hard for any of us to understand everything that an innocent person goes through when detained by the police. The recently released movie about The Stanford Prison Experiment may be an interesting place to start, a German version produced in 2001, Das Experiment, is also very highly respected.
The United States has the largest prison population in the world and the second-highest per-capita incarceration rate. Many, including some on death row, are actually innocent, in the wrong place at the wrong time, without the funds to hire an attorney. The system, and the police and prison officers who operate it, treat these people as packages on a conveyor belt, without even the most basic human dignity. Whether their encounter lasts for just a few hours or decades, is it any surprise that something dies inside them when they discover this cruel side of American society?
Worldwide, there is an increasing trend to make incarceration as degrading as possible. People may be innocent until proven guilty, but this hasn't stopped police in the UK from locking up and strip-searching over 4,500 children in a five year period, would these children go away feeling any different than if they had an encounter with Jimmy Saville or Rolf Harris? One can only wonder what they do to adults.
What all this boils down to is that people shouldn't really be incarcerated unless it is clear the danger they pose to society is greater than the danger they may face in a prison.
What can people do for Ian and for justice?
Now that these unfortunate smears have appeared, it would be great to try and fill the Internet with stories of the great things Ian has done for the world. Write whatever you feel about Ian's work and your own experience of Debian.
While the circumstances of the final tweets from his Twitter account are confusing, the tweets appear to be consistent with many other complaints about US law enforcement. Are there positive things that people can do in their community to help reduce the harm?
Sending books to prisoners (the UK tried to ban this) can make a difference. Treat them like humans, even if the system doesn't.
Recording incidents of police activities can also make a huge difference, such as the video of the shooting of Walter Scott or the UK police making a brutal unprovoked attack on a newspaper vendor. Don't just walk past a situation and assume everything is under control. People making recordings may find themselves in danger, it is recommended to use software that automatically duplicates each recording, preferably to the cloud, so that if the police ask you to delete such evidence, you can let them watch you delete it and still have a copy.
Can anybody think of awards that Ian Murdock should be nominated for, either in free software, computing or engineering in general? Some, like the prestigious Queen Elizabeth Prize for Engineering can't be awarded posthumously but others may be within reach. Come and share your ideas on the debian-project mailing list, there are already some here.
Best of all, Ian didn't just build software, he built an organization, Debian. Debian's principles have helped to unite many people from otherwise different backgrounds and carry on those principles even when Ian is no longer among us. Find out more, install it on your computer or even look for ways to participate in the project.
 I recently finished a paper that presents a novel social computing system called the Wikipedia Adventure. The system was a gamified tutorial for new Wikipedia editors. Working with the tutorial creators, we conducted both a survey of its users and a randomized field experiment testing its effectiveness in encouraging subsequent contributions. We found that although users loved it, it did not affect subsequent participation rates.
I recently finished a paper that presents a novel social computing system called the Wikipedia Adventure. The system was a gamified tutorial for new Wikipedia editors. Working with the tutorial creators, we conducted both a survey of its users and a randomized field experiment testing its effectiveness in encouraging subsequent contributions. We found that although users loved it, it did not affect subsequent participation rates.
 Start screen for the Wikipedia Adventure.
Start screen for the Wikipedia Adventure. The number of active, registered editors ( 5 edits per month) to Wikipedia over time. From Halfaker, Geiger, and Morgan 2012.
The number of active, registered editors ( 5 edits per month) to Wikipedia over time. From Halfaker, Geiger, and Morgan 2012. Survey responses about how users felt about TWA.
Survey responses about how users felt about TWA. Survey responses about what users learned through TWA.
Survey responses about what users learned through TWA.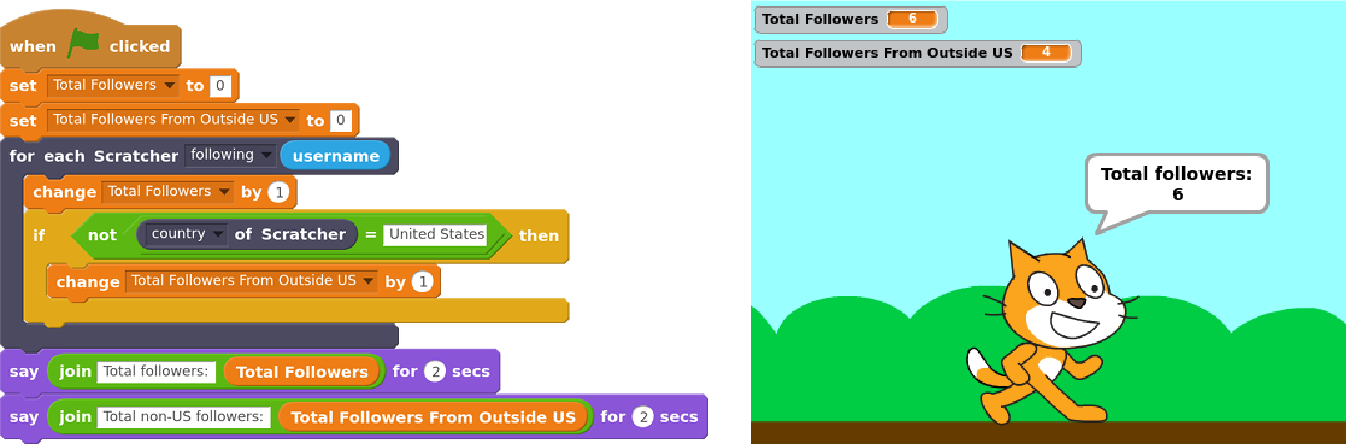
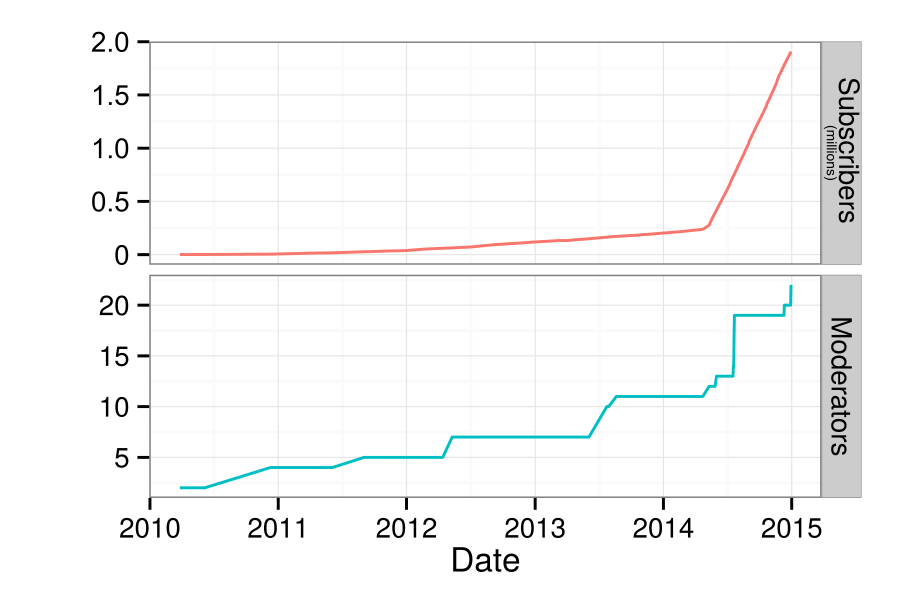
 Project metadata
Project metadata User metadata
User metadata Site-wide statistics
Site-wide statistics Simple demonstration of Scratch Community Blocks
Simple demonstration of Scratch Community Blocks Doughnut visualization
Doughnut visualization Ice-cream visualization
Ice-cream visualization Data-driven doll dress up
Data-driven doll dress up Like I wrote before,
Like I wrote before,  Earlier this week, I finally got my new machine that came with my
Earlier this week, I finally got my new machine that came with my 
 As some of the world knows full well by now, I've been noodling with Go
for a few years, working through its pros, its cons, and thinking a lot
about how humans use code to express thoughts and ideas. Go's got a lot of
neat use cases, suited to particular problems, and used in the right place,
you can see some clear massive wins.
I've started writing Debian tooling in Go, because it's a pretty natural fit.
Go's fairly tight, and overhead shouldn't be taken up by your operating system.
After a while, I wound up hitting the usual blockers, and started to build up
abstractions. They became pretty darn useful, so, this blog post is announcing
(a still incomplete, year old and perhaps API changing) Debian package for Go.
The Go importable name is
As some of the world knows full well by now, I've been noodling with Go
for a few years, working through its pros, its cons, and thinking a lot
about how humans use code to express thoughts and ideas. Go's got a lot of
neat use cases, suited to particular problems, and used in the right place,
you can see some clear massive wins.
I've started writing Debian tooling in Go, because it's a pretty natural fit.
Go's fairly tight, and overhead shouldn't be taken up by your operating system.
After a while, I wound up hitting the usual blockers, and started to build up
abstractions. They became pretty darn useful, so, this blog post is announcing
(a still incomplete, year old and perhaps API changing) Debian package for Go.
The Go importable name is  Started in 2008,
Started in 2008, 
 What happened in the
What happened in the 

